A Garfield-comic Search Engine

I can only guess that most of you never considered building a Garfield comic search engine. For me, though, that is not the case. This project has been swirling around in my brain for years already. As a kid, I was a big fan of the Garfield comic strips: I would go to the local library, borrow 16 books filled with comics, read all of them in one day, and then return for the next load. This obsession did not only span throughout my childhood, but also my teen years: I would ask my mother to get the Garfield school agenda for me, and I still have a Garfield key ring.
Now, about three years ago, in my first year of Computer Science, I stumbled on a little side project: "What if I could make a search engine for Garfield comics?”. I quickly found a website by a guy archiving all the Garfield comics published online [1], which sparked my inspiration. In this piece, I hope to take you with me on my journey of making my “Semantic Garfield Comic Search Engine”.
So, where do you get comics?
As I said above, I found this website hosting an archive of the Garfield comics, all ordered into years, months, and days of publishing. The simple nature of the website made it an easy task to download all the comics to my laptop with a simple Python script I wrote using the requests[2] and Beautiful Soup[3] libraries.
After the comics were scavenged (let's leave the legality of the cause in the middle), I started wondering what I could do with the data at hand…
Labelling Garfield
What I thought would be a simple and fast process turned out to be the reason I abandoned the project for two years. The problem at hand: labelling the data.
Here I set the goal of my project: having the ability to search through the comics, I needed a trustworthy way to associate the comics images with their content: the text inside the balloons, involved characters, emotions and the overall context of the comic.
Jim Davis, being a lazy guy, just like Garfield, didn't bother to make long comics, but rather limited himself to only three panels per day. “So, extracting the data shouldn't be that difficult?” I hear you asking. That's also what I thought.
As a first-year CSE student, I put on my programming pants and started coding away, forgetting to do any research. With a quick Google, I found Google's Tesseract OCR[4] project, which promised to provide amazing optical character recognition (OCR)
Optical Character Recognition (OCR) is a technology that converts different types of documents, like scanned paper or images, into editable and searchable text. It works by analysing the shapes of letters and numbers in the document and translating them into machine-readable characters.
Quickly, I downloaded the package and pulled a couple of comics through it… with absolutely worthless results. Then I started tweaking the images by turning them into greyscale and even only keeping the lines. I tried cutting up the comics into panels and even cutting the text balloons out of the panels using the OpenCV[5] library. All to discover that Tesseract is just bad at recognising the handwritten-like typography of Garfield.
Only after I had found an alternative solution to this problem two years later, I found a paper from a bachelor's thesis of a CSE student at TU Delft [6] who had done exactly what I couldn't do, even using similar techniques.
The introduction of Large Language Models (LLM)
After two frustrating years wrestling with OCR, I stumbled upon a completely different approach. I think that the title of this section already vaguely describes what my solution was to the labelling issue: I outsourced it to LLMs.
While big companies, whenever they need some data labelled cheaply, hire some overseas company to do the boring work, I hired a big company to do it for me. How? Well, let me introduce you to the OpenAI API. With a quick script, I sent all the comics to the `GPT-4o mini` model and commanded it to return me a structured file for every comic containing all the text, characters, colours, themes, emotions and much more for every comic. And you might think, “Didn't this cost you a fortune?”. Well, no, it cost me $10 to analyse all 3000 comics, but it might have been a bit more than I wanted to pay for this project initially.
Later in the process, when I needed some example queries to train the search algorithm with, I would return to the LLM tactic of generating dummy user input, but this time, because I didn't need the LLM to process images, the cost would come down to around $2 for a million of user queries generated, which is just so much less than the previous step.
Okay, now we can just search?
Well, no, not yet. To be able to search for comics, we need a way to transform the user query into a comic. To do this, I chose to train, or rather fine-tune, an encoder model. As a base, I decided to start with BERT [7] (which stands for Bidirectional Encoder Representations from Transformers). In layman's terms, BERT is a language model trained to transform (unlabelled) text into a vector in the embedding space. If you would like to learn more about how this works, I would recommend reading this blog post[8].
Now, back to my Garfield project. Let's define what we want in terms of input and output. As the input, we take the user input, which may be any text (like “birthday party” or “eating lasagna”), and as the output, we want multiple suggestions for Garfield comics, most suited for the input query. A keen observer might see a mismatch in the types of input and output, and this is where the embeddings come in.
For this project, I chose to build a “Two Tower” model, which, instead of training one model, trains two models to output the same, but with different inputs. In one tower, we pass the user input, and in the other, the comic metadata. During training, we modify model weights to output similar vectors, thus merging the embedding space of the comics with that of the queries.
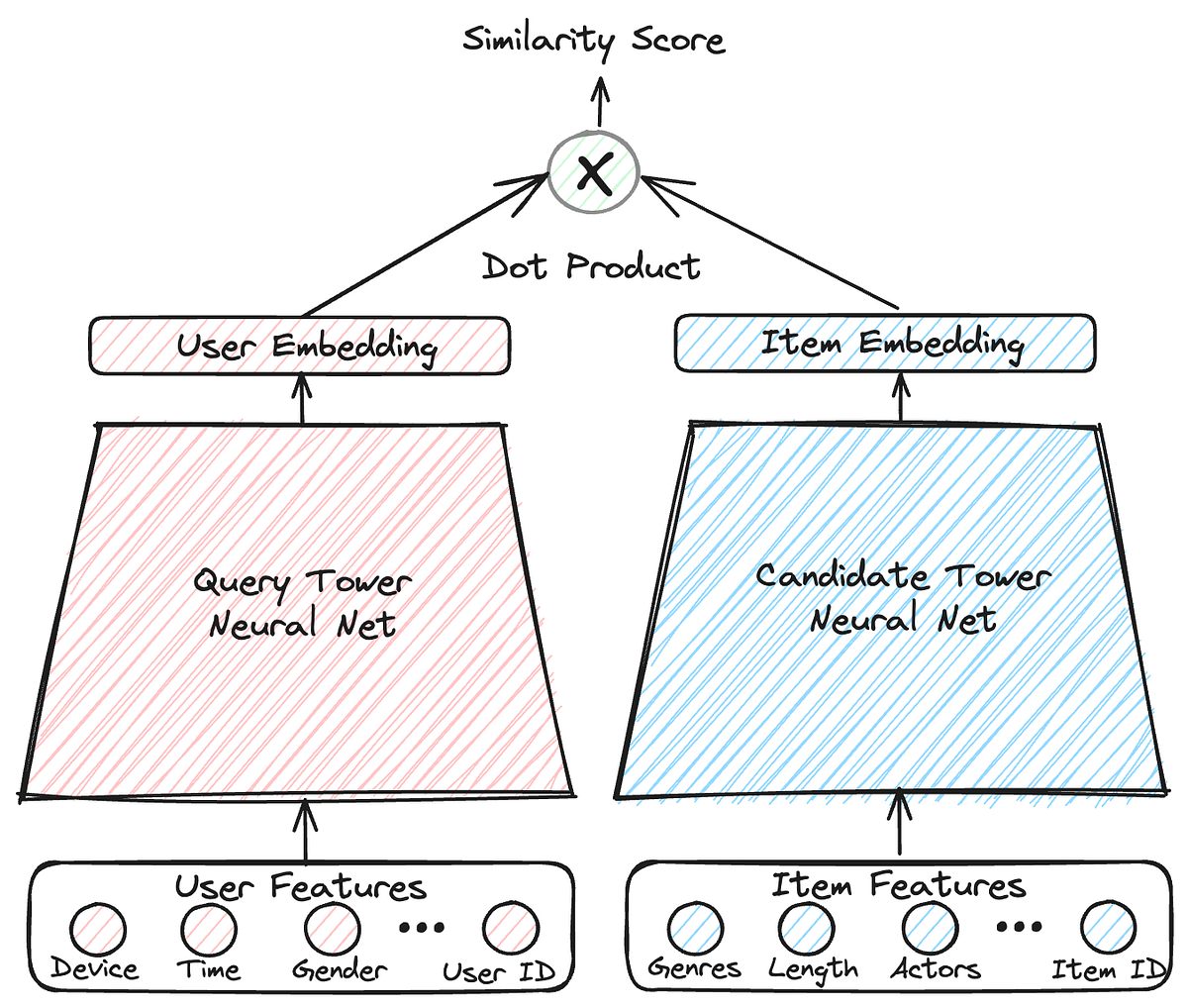
Now comes the neat part: after the training is complete, we generate embeddings for all the comics and store them in a vector database.
A vector database is a specialised type of database that stores data as vectors, which are mathematical representations of information in a high-dimensional space. It allows for efficient similarity searches and is commonly used in applications like machine learning, recommendations, and large language models.
Now in deployment, we only need to pass the user input through the query tower and find the comic embeddings which are closest to the query vector, and voilà, we have a Garfield comics search engine!
So, where can I try it?
Unfortunately, I am still working on the project by the time this article is published, so I cannot share a working deployment with you, but hopefully, soon this project will be online!
Conclusion
I hope you enjoyed reading about my passion project as much as I liked sharing my work with you. While this project may seem useless and a waste of time, at least I had fun discovering new machine-learning techniques and writing this article. My goal here is also to inspire you, the reader, to go on a little computer adventure of your own and turn your imagination into reality.
This article was published in “Machazine” 2024–2025 Q4 edition, the magazine of the Study Association W.I.S.V. Christiaan Huygens (TU Delft)
References
- “Garfield comics.” http://pt.jikos.cz/garfield/
- “Requests: HTTP for HumansTM — Requests 2.32.3 documentation.” https://docs.python-requests.org/en/latest/index.html
- L. Richardson, “Beautiful Soup: We called him Tortoise because he taught us.” https://www.crummy.com/software/BeautifulSoup/
- “Tesseract OCR,” Tessdoc. https://tesseract-ocr.github.io/tessdoc/Home.html
- OpenCV, “OpenCV - Open Computer Vision Library,” OpenCV, May 02, 2025. https://opencv.org/
- M. Styczeń, “Automated Text-Image Comic Dataset Construction,” 2021. https://resolver.tudelft.nl/uuid:4cd4da94-d762-4985-ac30-00ee81e33e63
- J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” arXiv.org, Oct. 11, 2018. https://arxiv.org/abs/1810.04805
- M. Mansurova, “Text Embeddings: Comprehensive guide,” Towards Data Science, Jan. 23, 2025. https://towardsdatascience.com/text-embeddings-comprehensive-guide-afd97fce8fb5/
- Hawe, S. (2024, December 23). Video recommendations at Joyn: Two tower or not to tower, that was never a question | By Simon Hawe | ProSiebenSat.1 Tech Blog | 2023 | Medium | ProSiebenSat.1 Tech Blog. Medium. https://medium.com/tech-p7s1/video-recommendations-at-joyn-two-tower-or-not-to-tower-that-was-never-a-question-6c6f182ade7c