The Hidden Signature of AI

Imagine scrolling through your social media feed and noticing a flood of identical, opinionated posts. Sounds familiar? The culprit, or culprits, are the ever more popular Large Language Model (LLM) algorithms, producing those kinds of posts in just seconds. Such an explosive growth of AI-generated text on the internet has raised concerns about misinformation, fake news, and (accidental) academic fraud. To alleviate this problem, Kirchenbauer et al. [1] have developed a method to watermark text generated by LLMs. By embedding detectable signals into text, watermarking provides a reliable method for detecting AI-generated text.
The Rise of LLMs
LLMs have changed how we communicate, work, learn and even create art. These AI models produce coherent essays, generate code, and even pretend to be your friend. However, with these tools being widely accessible, some risks arise — misinformation can spread unchecked, academic standards may be undermined, and last but not least, LLMs need to know if the information they train on is not generated. This highlights the importance of a reliable method for detecting AI-generated content.
What is Text Watermarking?

Text watermarking is an ancient art: in the golden age of kingdoms, it was essential to confirm the legitimacy of documents. In Fabriano, Italy, a new technique was invented in the 13th century [2]. While manufacturing paper, its thickness would be altered in specific spots while it was still wet. This way, when the paper was held up to a light source, the watermark was visible, as you can see in Figure 1. You, however, may link the word watermark to the option in word processors of today, where an ugly text is overlaid over the actual text to indicate that a document is still a draft or to indicate confidentiality.
While the examples above are very detectable watermarking techniques, today’s topic is a more nuanced way of marking text. You may have heard about the Tesla “email watermark” which they used to include in confidential emails [3]. The email software would randomly replace spaces with double spaces, uniquely for every recipient. This way, if the information was leaked, the leak source could be found by comparing the spaces in the leaked document.
You may have guessed that this method, however, is not very durable. The spaces can be randomised by the leaker, or if a screenshot is leaked, it’s practically impossible to check the spaces. Also, when rendering HTML, multiple spaces are merged, thus rendering the space information unreadable. While this small example is a nice demonstration of how NOT to watermark text, a question arises: how can we durably watermark text, without affecting the actual content of the text?
How To Implement Watermarking in Large Language Models?
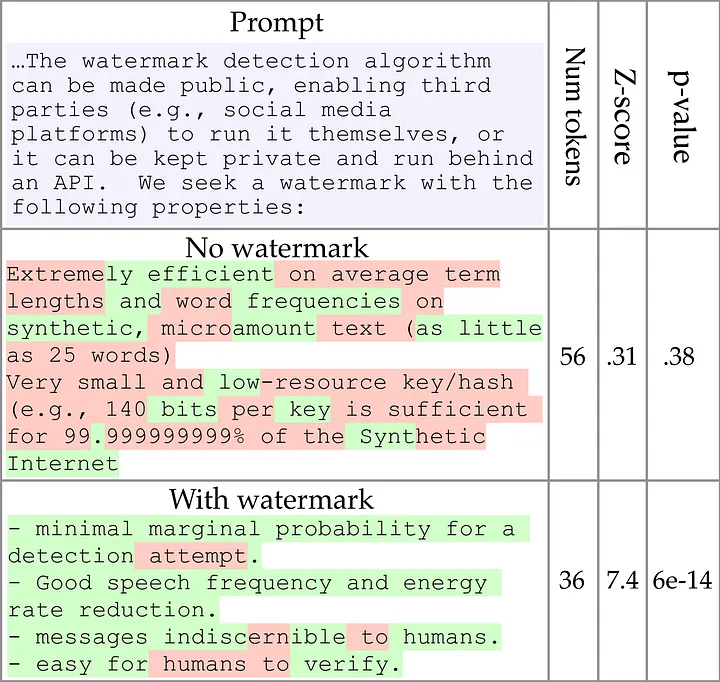
Kirchenbauer et al. [1] have invented a framework for watermarking LLM texts while preserving the text quality. The researchers suggest embedding signals, invisible to humans, in the text, which can be algorithmically detected from a text with a length as small as 25 tokens.
The method proposes that all tokens in the embedding space of the LLM, get marked red or green. The output of the LLM may only consist of green tokens. The division of green or red tokens is done again for every token t[i], where the previous token t[i-1] is hashed, and the hash is then used as the seed for a pseudo-random number generator. This way, the selection of red and green tokens is updated every time a new output token is produced.
This approach, however effective, degrades quickly in low-entropy situations, where the obvious word choice might get red-listed, which will affect the output text quality. To address this issue, the researchers introduce a “soft” watermarking approach, where rather than forbidding the LLM to use the words in the red list, we add a constant value δ to the probabilities of green tokens, subtly biasing the model to choose green words. This adaptation of the algorithm preserves the word choices for low-entropy text, while still creating a detectable watermark in high-entropy sections.
The detection mechanism of this watermark is then rather simple: in a pass through the text, we use the hash of t[i-1] to calculate the green list for the next token t[i]. We then check for every word whether it’s green or red. The count of the red tokens is then compared against the expected random distribution, and a z-statistic is then generated with interpretable p-values. This is called the one-proportion z-test, and enables confident detection with a small chance of false positives, even for short text fragments.
Benefits, Challenges and Experimental Insights
The described method provides us with a robust text watermark that can be used by LLM vendors to confirm the origin of the text. Furthermore, the authors of the paper suggest that the watermark stays detectable until approximately 25% of the text is altered. The suggested approach also doesn’t require access to the LLM API or its parameters, which makes it possible to open-source the watermark detection algorithm. However, if the entirety of the text consists of low-entropy segments, the watermark will not perform as well. In this situation, though, we should ask ourselves if the watermarking is even useful if the text is so widely used that the LLM reproduces it exactly.
Experimental insights from testing with multi-billion parameter open source transformer models demonstrate that detection can yield interpretable p-values with minimal false positives as low as 3×10^-5 for certain thresholds. This statistical approach enables third parties to confidently identify synthetic content with p-values as extreme as 6×10^-14, providing a robust mechanism for distinguishing between human and machine-generated text [1].
Conclusion
This technology is significant beyond just detection. By enabling the transparent identification of AI-generated content, watermarking creates accountability in LLM usage and deployment and helps to keep information integrity across the internet. Universities can better uphold academic standards; news organizations can verify content authenticity; and even LLM developers can train better models by consciously excluding AI-generated data from the training dataset [1].
Looking forward, the evolution of watermarking techniques will likely lead to an innovation “Battle Royale” between LLM developers and researchers. As AI systems continue to improve, the technical measures we implement today may determine whether the Internet of tomorrow will maintain its integrity or become confusing as hell. The challenge remains to develop watermarking approaches that can adapt to various writing styles and contexts while remaining resilient against removal attempts.
Yet, effective watermarking represents not just a technical achievement but a crucial step toward responsible AI development — ensuring that as language models become more integrated into our communication infrastructure, we maintain the ability to distinguish between human and synthetic voices.
This article was published in “Machazine” 2024–2025 Q3 edition, the magazine of the Study Association W.I.S.V. Christiaan Huygens (TU Delft)
References
[1] Kirchenbauer, J., Geiping, J., Wen, Y., Katz, J., Miers, I., & Goldstein, T. (2023). A Watermark for Large Language Models. In Proceedings of the 40th International Conference on Machine Learning (pp. 17061–17084). PMLR. Available from https://proceedings.mlr.press/v202/kirchenbauer23a.html.
[2] Meggs, P. B., & Purvis, A. W. (2006). Meggs’ history of graphic design. John Wiley & Sons, Inc. p. 58. ISBN 978–0–471–29198–5.
[3] Mazurov, N. (2022, December 15). How Elon Musk says he catches leakers at his companies. The Intercept. https://theintercept.com/2022/12/15/elon-musk-leaks-twitter/